BEAR: Benchmarking and Enhancing Multimodal Language Models for
Atomic Embodied Capabilities
 Paper
Paper
Introduction
Embodied agents require a range of perceptual and reasoning skills—from low-level sensing to high-level planning. Recent works highlights the potential of Multimodal Large Language Models (MLLMs) as embodied agents. Yet, a holistic benchmark evaluating step-wise embodied skills remains absent.
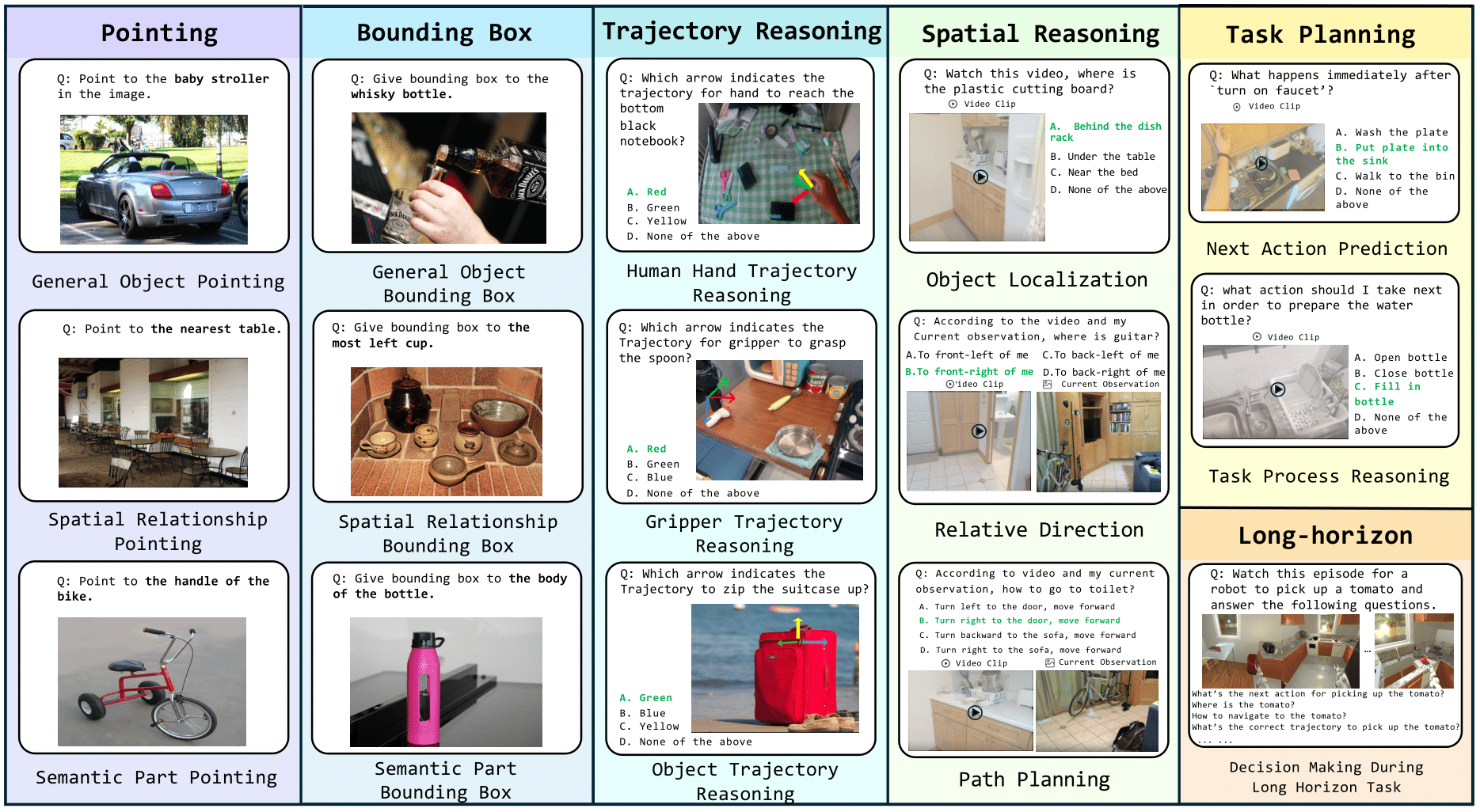
To bridge this gap, we introduce BEAR, a benchmark of 4,469 interleaved image–video–text VQA samples spanning perception to planning. Our systematic evaluation of 20 representative MLLMs and failure analysis reveal that current MLLMs are limited by a lack of omni-visual and 3D spatial abilities.
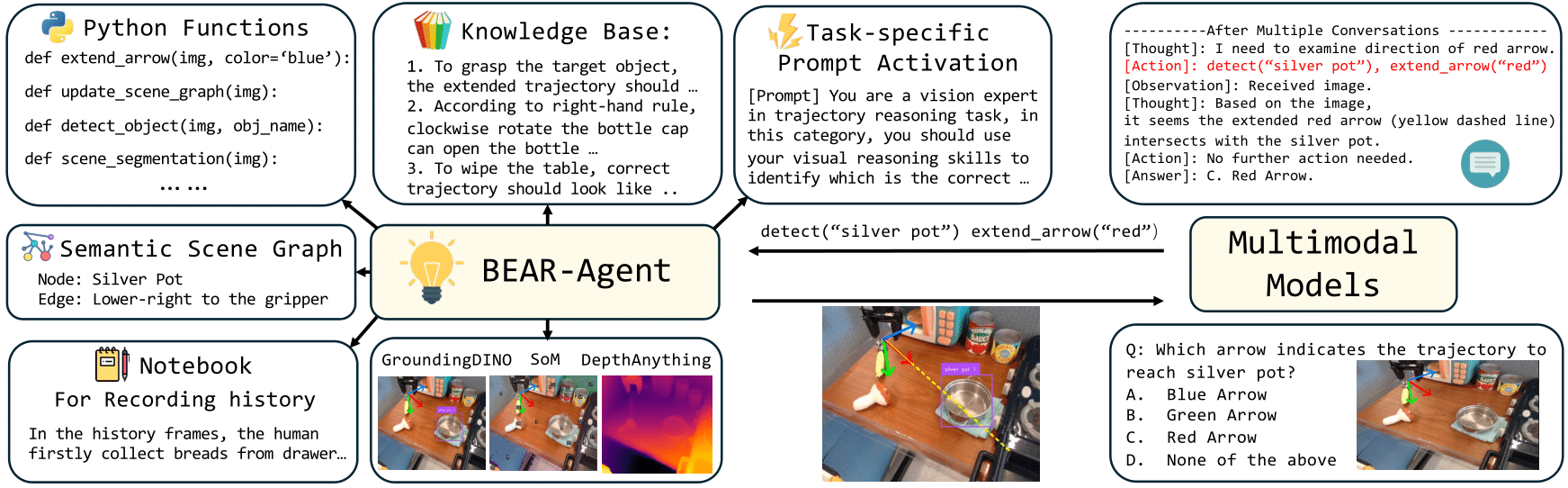
Motivated by failure analysis, we introduce BEAR-Agent, a multimodal conversable agent that leverages visual tools to enhance MLLMs’ embodied capabilities. BEAR‑Agent significantly boosts InternVL3‑14B and GPT‑5's performance on BEAR. Moreover, our tabletop manipulation experiments demonstrate its potential as a step toward general embodied agents.